ML Metadata
导语:
本文是 tensorflow 手册翻译系列的第三十六篇。
本文档介绍机器学习元数据。
目录
- MLMD启用的功能
- 元数据后台存储和存储链接配置
- 元数据存储
-
- 概念
-
- 使用机器元数据跟踪机器学习流
-
- 使用远程 grpc 服务器
正文
ML元数据(MLMD)是一个用于记录和检索与ML开发人员和数据科学家工作流程相关联的元数据的库。 MLMD是TensorFlow Extended(TFX)不可或缺的一部分,但其设计使其可以独立使用。作为更广泛的TFX平台的一部分,大多数用户仅在检查管道组件的结果时才与MLMD交互,例如在笔记本电脑或TensorBoard中。
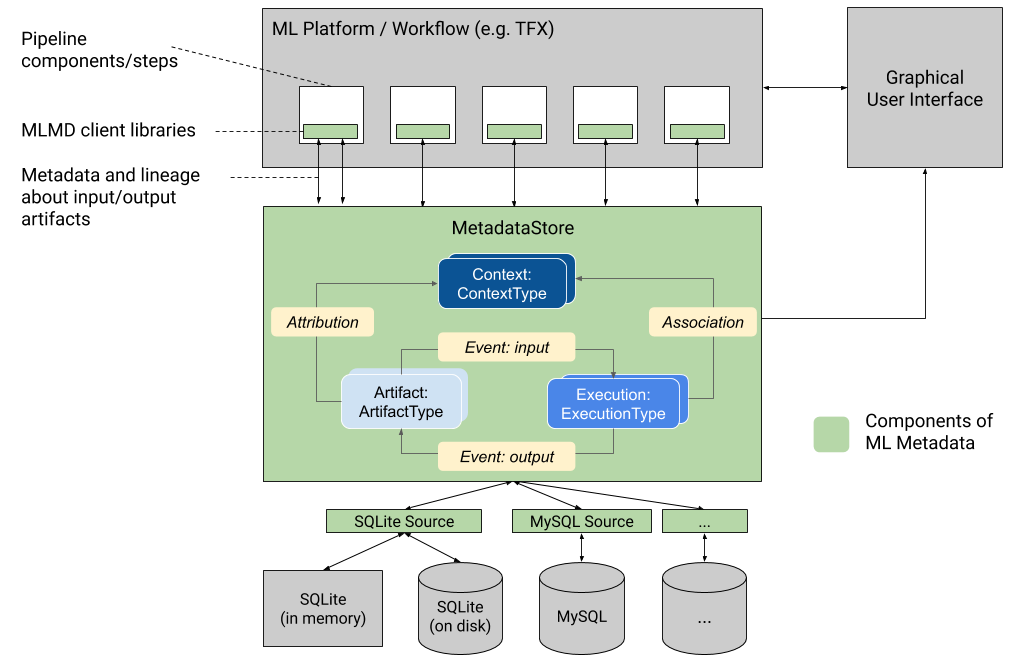
下图显示了MLMD的组成部分。存储后端是可插入的,可以扩展。 MLMD提供了现成的SQLite(支持内存和磁盘)和MySQL的参考实现。 MetadataStore提供了API,用于在存储后端之间记录和检索元数据。 MLMD可以注册:
关于通过管道的组件/步骤生成的工件的元数据 有关这些组件/步骤执行的元数据 有关管道的元数据和相关的沿袭信息 下面将详细解释这些概念。
MLMD启用的功能 跟踪ML工作流中所有组件/步骤的输入和输出及其沿袭,可以使ML平台启用多个重要功能。以下列表提供了一些主要优点的详尽介绍。
列出特定类型的所有工件。示例:所有经过训练的模型。 加载两个相同类型的工件以进行比较。示例:比较两个实验的结果。 显示所有相关执行及其上下文的输入和输出工件的DAG。示例:可视化调试和发现实验的工作流程。 遍历所有事件以查看工件是如何创建的。示例:查看将哪些数据纳入模型;实施数据保留计划。 标识使用给定工件创建的所有工件。示例:查看从特定数据集中训练的所有模型;根据不良数据标记模型。 确定以前是否在相同的输入上运行过执行。示例:确定某个组件/步骤是否已经完成相同的工作,并且先前的输出可以重复使用。 记录和查询工作流运行的上下文。示例:跟踪用于工作流运行的所有者和变更列表;通过实验对血统进行分组;按项目管理工件。 元数据存储后端和存储连接配置 MetadataStore对象接收与使用的存储后端相对应的连接配置。
Fake Database提供了一个内存数据库(使用SQLite)来进行快速实验和本地运行。销毁存储对象时,将删除数据库。
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.fake_database.SetInParent() # Sets an empty fake database proto.
store = metadata_store.MetadataStore(connection_config)
SQLite从磁盘读取和写入文件。
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.sqlite.filename_uri = '...'
connection_config.sqlite.connection_mode = 3 # READWRITE_OPENCREATE
store = metadata_store.MetadataStore(connection_config)
MySQL连接到MySQL服务器。
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.mysql.host = '...'
connection_config.mysql.port = '...'
connection_config.mysql.database = '...'
connection_config.mysql.user = '...'
connection_config.mysql.password = '...'
store = metadata_store.MetadataStore(connection_config)
元数据存储 概念 元数据存储使用以下数据模型来记录和从存储后端检索元数据。
ArtifactType描述了工件的类型及其存储在元数据存储中的属性。这些类型可以通过代码在Metadata Store中即时注册,也可以从序列化格式加载到存储中。注册类型后,其定义在商店的整个生命周期中都可用。 Artifact描述了ArtifactType的特定实例及其写入元数据存储的属性。 ExecutionType描述工作流程中组件或步骤的类型及其运行时参数。 执行是组件运行或ML工作流中的步骤以及运行时参数的记录。执行可以认为是ExecutionType的实例。每次开发人员运行ML管道或步骤时,都会记录每个步骤的执行情况。 事件是工件与执行之间关系的记录。执行发生时,事件会记录执行所使用的每个工件,以及所产生的每个工件。这些记录允许在整个工作流程中进行出处跟踪。通过查看所有事件,MLMD知道发生了什么执行,结果创建了哪些工件,并且可以从任何工件返回到其所有上游输入。 ContextType描述了工作流中的工件和执行的概念性组的类型及其结构属性。例如:项目,管道运行,实验,所有者。 上下文是ContextType的实例。它捕获组内的共享信息。例如:项目名称,变更列表提交ID,实验注释。它在其ContextType中具有用户定义的唯一名称。 归因是工件与上下文之间关系的记录。 关联是执行和上下文之间关系的记录。 使用ML元数据跟踪ML工作流 下图描述了如何使用低级ML元数据API跟踪培训任务的执行情况,随后是代码示例。请注意,本节中的代码显示了ML平台开发人员将使用ML元数据API来将其平台与ML Metadata集成,而不是直接由开发人员使用。此外,我们将提供更高级别的Python API,供笔记本电脑环境中的数据科学家用来记录他们的实验元数据。
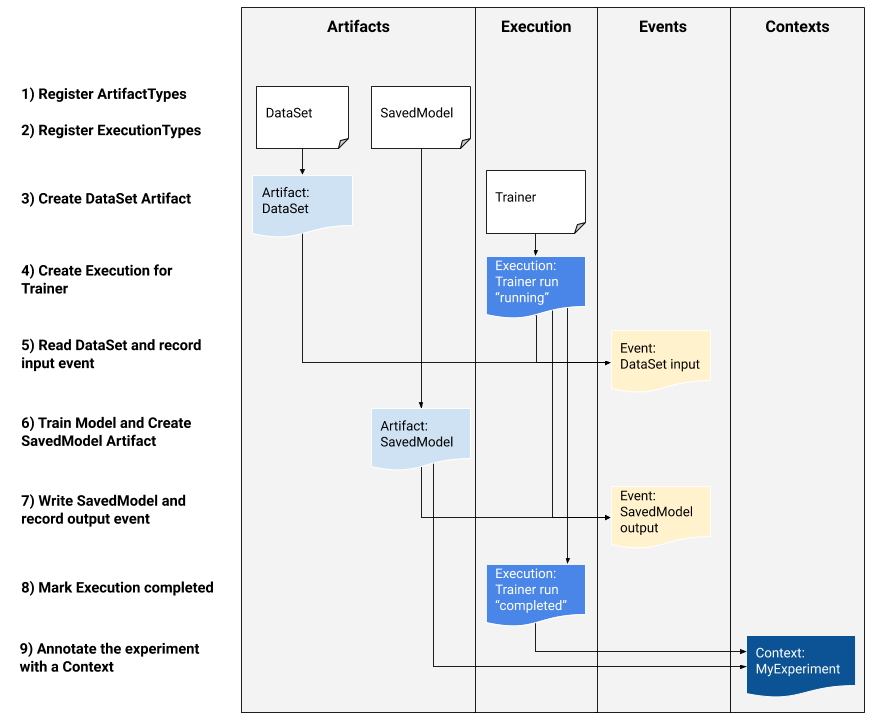
1)在可以记录执行之前,必须注册ArtifactTypes。
# Create ArtifactTypes, e.g., Data and Model
data_type = metadata_store_pb2.ArtifactType()
data_type.name = "DataSet"
data_type.properties["day"] = metadata_store_pb2.INT
data_type.properties["split"] = metadata_store_pb2.STRING
data_type_id = store.put_artifact_type(data_type)
model_type = metadata_store_pb2.ArtifactType()
model_type.name = "SavedModel"
model_type.properties["version"] = metadata_store_pb2.INT
model_type.properties["name"] = metadata_store_pb2.STRING
model_type_id = store.put_artifact_type(model_type)
2)在记录执行之前,必须为我们的ML工作流中的所有步骤注册ExecutionTypes。
# Create ExecutionType, e.g., Trainer
trainer_type = metadata_store_pb2.ExecutionType()
trainer_type.name = "Trainer"
trainer_type.properties["state"] = metadata_store_pb2.STRING
trainer_type_id = store.put_execution_type(trainer_type)
3)一旦类型被注册,我们就创建一个数据集工件。
# Declare input artifact of type DataSet
data_artifact = metadata_store_pb2.Artifact()
data_artifact.uri = 'path/to/data'
data_artifact.properties["day"].int_value = 1
data_artifact.properties["split"].string_value = 'train'
data_artifact.type_id = data_type_id
data_artifact_id = store.put_artifacts([data_artifact])
4)创建数据集工件后,我们可以为教练运行创建执行
# Register the Execution of a Trainer run
trainer_run = metadata_store_pb2.Execution()
trainer_run.type_id = trainer_type_id
trainer_run.properties["state"].string_value = "RUNNING"
run_id = store.put_executions([trainer_run])
5)声明输入事件并读取数据。
# Declare the input event
input_event = metadata_store_pb2.Event()
input_event.artifact_id = data_artifact_id
input_event.execution_id = run_id
input_event.type = metadata_store_pb2.Event.DECLARED_INPUT
# Submit input event to the Metadata Store
store.put_events([input_event])
6)现在输入已被读取,我们声明输出工件。
# Declare output artifact of type SavedModel
model_artifact = metadata_store_pb2.Artifact()
model_artifact.uri = 'path/to/model/file'
model_artifact.properties["version"].int_value = 1
model_artifact.properties["name"].string_value = 'MNIST-v1'
model_artifact.type_id = model_type_id
model_artifact_id = store.put_artifacts(model_artifact)
7)创建模型工件后,我们可以记录输出事件。
# Declare the output event
output_event = metadata_store_pb2.Event()
output_event.artifact_id = model_artifact_id
output_event.execution_id = run_id
output_event.type = metadata_store_pb2.Event.DECLARED_OUTPUT
# Submit output event to the Metadata Store
store.put_events([output_event])
8)现在已记录了所有内容,可以将执行标记为已完成。
trainer_run.id = run_id
trainer_run.id.properties["state"].string_value = "COMPLETED"
store.put_executions([trainer_run])
9)然后,工件和执行可以分组到一个上下文中(例如,实验)。
# Similarly, create a ContextType, e.g., Experiment with a `note` property
experiment_type = metadata_store_pb2.ContextType()
experiment_type.name = "Experiment"
experiment_type.properties["note"] = metadata_store_pb2.STRING
experiment_type_id = store.put_context_type(experiment_type)
# Group the model and the trainer run to an experiment.
my_experiment = metadata_store_pb2.Context()
my_experiment.type_id = experiment_type_id
# Give the experiment a name
my_experiment.name = "exp1"
my_experiment.properties["note"].string_value = "My first experiment."
experiment_id = store.put_contexts([my_experiment])
attribution = metadata_store_pb2.Attribution()
attribution.artifact_id = model_artifact_id
attribution.context_id = experiment_id
association = metadata_store_pb2.Association()
association.execution_id = run_id
attribution.context_id = experiment_id
store.put_attributions_and_associations([attribution], [association])
使用远程grpc服务器 1)启动服务器
bazel run -c opt --define grpc_no_ares=true //ml_metadata/metadata_store:metadata_store_server
2)创建客户端存根,并在python中使用它
from grpc import insecure_channel
from ml_metadata.proto import metadata_store_pb2
from ml_metadata.proto import metadata_store_service_pb2
from ml_metadata.proto import metadata_store_service_pb2_grpc
channel = insecure_channel('localhost:8080')
stub = metadata_store_service_pb2_grpc.MetadataStoreServiceStub(channel)
3)将MLMD与RPC调用一起使用
# Create ArtifactTypes, e.g., Data and Model
data_type = metadata_store_pb2.ArtifactType()
data_type.name = "DataSet"
data_type.properties["day"] = metadata_store_pb2.INT
data_type.properties["split"] = metadata_store_pb2.STRING
request = metadata_store_service_pb2.PutArtifactTypeRequest()
request.all_fields_match = True
request.artifact_type.CopyFrom(data_type)
stub.PutArtifactType(request)
model_type = metadata_store_pb2.ArtifactType()
model_type.name = "SavedModel"
model_type.properties["version"] = metadata_store_pb2.INT
model_type.properties["name"] = metadata_store_pb2.STRING
request.artifact_type.CopyFrom(model_type)
stub.PutArtifactType(request)