The ExampleGen TFX Pipeline Component
导语:
本文是 tensorflow 手册翻译系列的第十一篇。
本文档详细介绍了 ExampleGen 组件的作用。
目录
- ExampleGen 和其他组件
- 如何使用一个 ExampleGen 组件
- 间隔、版本和分割
-
- 自定义输入和输出分割
-
- 间隔
-
- 版本
- 自定义 ExampleGen
-
- 文件基础的 ExampleGen
-
- 查询基础的 ExampleGen
正文
ExampleGen TFX Pipeline组件将数据提取到TFX管道中。它使用外部文件/服务来生成示例,其他TFX组件将读取这些示例。它还提供了一致且可配置的分区,并为ML最佳实践改组了数据集。
消耗:来自外部数据源(例如CSV,TFRecord和BigQuery)的数据 排放:tf。示例记录 ExampleGen和其他组件 ExampleGen将数据提供给使用TensorFlow数据验证库的组件,例如SchemaGen,StatisticsGen和Example Validator。它还向使用TensorFlow Transform库的Transform提供数据,并最终在推理期间为部署目标提供数据。
如何使用ExampleGen组件 对于受支持的数据源(当前是CSV文件,带有TF Example数据格式的TFRecord文件以及BigQuery查询的结果),ExampleGen管道组件通常非常易于部署,几乎不需要自定义。典型的代码如下所示:
from tfx.utils.dsl_utils import csv_input
from tfx.components.example_gen.csv_example_gen.component import CsvExampleGen
examples = csv_input(os.path.join(base_dir, 'data/simple'))
example_gen = CsvExampleGen(input=examples)
或如下所示,直接导入外部tf示例:
from tfx.utils.dsl_utils import tfrecord_input
from tfx.components.example_gen.import_example_gen.component import ImportExampleGen
examples = tfrecord_input(path_to_tfrecord_dir)
example_gen = ImportExampleGen(input=examples)
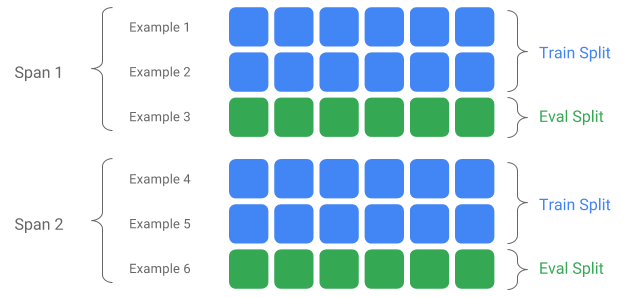
跨度,版本和拆分 跨度是一组训练示例。 如果您的数据保留在文件系统上,则每个跨度都可以存储在单独的目录中。 Span的语义不会硬编码到TFX中。 跨度可能对应于一天的数据,一个小时的数据或对您的任务有意义的任何其他分组。
每个跨度可以保存多个版本的数据。 举例来说,如果您从Span中删除一些示例以清除质量较差的数据,则可能会导致该Span出现新版本。 默认情况下,TFX组件在跨度内的最新版本上运行。
跨度内的每个版本可以进一步细分为多个拆分。 拆分Span的最常见用例是将其拆分为训练和评估数据。
自定义输入/输出拆分 注意:此功能仅在TFX 0.14之后可用。 要自定义ExampleGen将输出的火车/评估分配比,请为ExampleGen组件设置output_config。 例如:
from tfx.proto import example_gen_pb2
# Input has a single split 'input_dir/*'.
# Output 2 splits: train:eval=3:1.
output = example_gen_pb2.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
example_gen_pb2.SplitConfig.Split(name='train', hash_buckets=3),
example_gen_pb2.SplitConfig.Split(name='eval', hash_buckets=1)
]))
examples = csv_input(input_dir)
example_gen = CsvExampleGen(input=examples, output_config=output)
注意在此示例中如何设置hash_buckets。
对于已拆分的输入源,请为ExampleGen组件设置input_config:
from tfx.proto import example_gen_pb2
# Input train split is 'input_dir/train/*', eval split is 'input_dir/eval/*'.
# Output splits are generated one-to-one mapping from input splits.
input = example_gen_pb2.Input(splits=[
example_gen_pb2.Input.Split(name='train', pattern='train/*'),
example_gen_pb2.Input.Split(name='eval', pattern='eval/*')
])
examples = csv_input(input_dir)
example_gen = CsvExampleGen(input=examples, input_config=input)
对于基于文件的示例gen(例如CsvExampleGen和ImportExampleGen),pattern是一个glob相对文件模式,它映射到输入文件,其根目录由输入基本路径给定。对于基于查询的示例gen(例如BigQueryExampleGen,PrestoExampleGen),模式是SQL查询。
默认情况下,整个输入基目录被视为单个输入拆分,并且火车和评估输出拆分以2:1的比率生成。
有关详细信息,请参考proto / example_gen.proto。
跨度 注意:此功能仅在TFX 0.15之后可用。 可以通过在输入glob模式中使用“ {SPAN}”规范来检索跨度:
该规范匹配数字并将数据映射到相关的SPAN数字中。例如,“ data_ {SPAN}-*。tfrecord”将收集“ data_12-a.tfrecord”,“ date_12-b.tfrecord”之类的文件。 如果缺少SPAN规范,则假定其始终为跨度’0’。 如果指定了SPAN,则管道将处理最新的跨度,并将跨度号存储在元数据中 例如,假设有输入数据:
’/ tmp / span-01 / train / data’ ‘/ tmp / span-01 / eval / data’ ‘/ tmp / span-02 / train / data’ ‘/ tmp / span-02 / eval / data’ 输入配置如下所示:
splits {
name: 'train'
pattern: 'span-{SPAN}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/eval/*'
}
触发管道时,它将处理:
’/ tmp / span-02 / train / data’作为火车拆分 ‘/ tmp / span-02 / eval / data’作为eval拆分 跨度号为“ 02”。 如果稍后在’/ tmp / span-03 / …‘上准备就绪,只需再次触发管道,它将拾取跨度’03’进行处理。 下面显示了使用span规范的代码示例:
from tfx.proto import example_gen_pb2
input = example_gen_pb2.Input(splits=[
example_gen_pb2.Input.Split(name='train',
pattern='span-{SPAN}/train/*'),
example_gen_pb2.Input.Split(name='eval',
pattern='span-{SPAN}/eval/*')
])
examples = csv_input('/tmp')
example_gen = CsvExampleGen(input=examples, input_config=input)
注意:尚不支持检索某个范围。 您现在只能修复此模式(例如,使用“ span-2 / eval /”而不是“ span- {SPAN} / eval /”),但是通过这样做,存储在元数据中的跨度编号将为零。 版 注意:尚不支持版本 自定义ExampleGen 注意:此功能仅在TFX 0.14之后可用。 如果当前可用的ExampleGen组件不符合您的需求,请创建一个自定义ExampleGen,它将包含从BaseExampleGenExecutor扩展的新执行程序。
基于文件的ExampleGen 首先,使用自定义的Beam PTransform扩展BaseExampleGenExecutor,该转换提供从火车/评估输入拆分到TF示例的转换。 例如,CsvExampleGen执行程序提供从输入CSV拆分到TF示例的转换。
然后,使用上述执行程序创建一个组件,就像在CsvExampleGen组件中一样。 或者,将自定义执行程序传递到标准ExampleGen组件中,如下所示。
from tfx.components.base import executor_spec
from tfx.components.example_gen.component import FileBasedExampleGen
from tfx.components.example_gen.csv_example_gen import executor
from tfx.utils.dsl_utils import external_input
examples = external_input(os.path.join(base_dir, 'data/simple'))
example_gen = FileBasedExampleGen(
input=examples,
custom_executor_spec=executor_spec.ExecutorClassSpec(executor.Executor))
现在,我们还支持使用此方法读取Avro和Parquet文件。
基于查询的ExampleGen 首先,使用自定义的Beam PTransform扩展BaseExampleGenExecutor,该自定义的Beam PTransform可从外部数据源读取。 然后,通过扩展QueryBasedExampleGen创建一个简单的组件。
这可能需要也可能不需要其他连接配置。 例如,BigQuery执行程序使用默认的beam.io连接器进行读取,该连接器抽象了连接配置详细信息。 Presto执行器需要一个自定义Beam PTransform和一个自定义连接配置protobuf作为输入。
如果自定义ExampleGen组件需要连接配置,则创建一个新的protobuf并将其传递到custom_config中,该参数现在是可选的执行参数。 以下是如何使用已配置组件的示例。
from tfx.examples.custom_components.presto_example_gen.proto import presto_config_pb2
from tfx.examples.custom_components.presto_example_gen.presto_component.component import PrestoExampleGen
presto_config = presto_config_pb2.PrestoConnConfig(host='localhost', port=8080)
example_gen = PrestoExampleGen(presto_config, query='SELECT * FROM chicago_taxi_trips')