Architecture
导语:
本文是 tensorflow 手册翻译系列的第三篇。
本篇描述了 tensorflow 服务的体系结构。通过对结构的深入,可以加深进一步的理解。
目录
- 关键概念
-
- 可服务化
-
- 加载器
-
- 源
-
- 管理器
-
- 核心
- 可服务化的生命周期
- 可扩充性
-
- 版本处理
-
- 源
-
- 加载器
-
- 批处理器
正文
tensorflow 服务是一个灵活的,高性能的机器学习模型服务系统,定位于生产环境。tensorflow 服务使得保持相同的系统服务结构和 API 部署新的算法和实验更加的简单。tensorflow 提供了开箱即用的 部署新的算法和实验更加的简单。tensorflow 集成模型,从而可以轻易的扩展提供服务的模型类型。
关键概念
为了理解 tensorflow 服务的系统结构,你需要理解以下关键点概念:
可服务化
可服务化是 tensorflow 服务里的核心概念抽象。可服务化是客户端执行计算的基础对象,例如在查询和推理时。
服务的大小和粒度是灵活的。一个独立的服务可能包括从查找表的单个碎片到一个模型到一组推理模型的任何内容。可服务化可以是任何类型和接口,它的灵活性和未来可改进性包括如下:
- 流式结果
- 实验性的 API
- 异步的操作模型
可服务化并不管理它们自己的生命周期。
传统的可服务化包括如下内容:
- 一个 tensorflow 保存模型捆绑包: tensorflow::Session
- 用于嵌入或词汇查找的查找表
可服务化版本
tensorflow 服务可以处理一个或多个可服务化的版本,在一个服务实例的生命周期内。这样可以随着时间的推移,逐步加载新的算法配置、权重和其他数据。版本使可服务化的一个以上版本可以同时加载,从而支持逐步推理和实验。在服务时,客户可以针对特定型号请求最新版本或特定版本 ID。
可服务化流
一个可服务化流是按照版本号递增排序的可服务版本的序列。
模型
tensorflow 服务将模型表示为一个或多个可服务对象。机器学习的模型可以包括一个或多个算法,包括学习的权重以及查找表或嵌入表。
你可以将复合模型表示为以下任意一种:
- 多个独立的可服务对象
- 一个复合的可服务对象
可服务对象也可以对应于模型的一部分。例如,可以在许多 tensorflow 服务实例之间共享大型查找表。
加载器
加载器管理着一个可服务对象的生命周期。加载器 API 可以支持独立于特定学习算法,数据或产品用例的通用基础架构。具体来说,加载程序会标准化用于加载和卸载的可服务对象的 API。
源
源是查找并提供可服务项的插件模块。每个源可以提供0或更多的可服务化流。对每个可服务化流,源都提供一个加载器实例给每个可用版本在加载时。一个源实际上是与0或多个 SourceAdapters 链接在一起的,其中该链的最后一项启动加载器。
TensorFlow 服务源的界面可以发现任意存储系统中的可服务化对象。TensorFlow 服务包括了一般的源的实现。例如,源可以以 RPC 机制进入,并对文件系统轮询。
源可以维护在多个可服务对象或版本之间共享的状态。这对于在版本之间使用 delta 增量 diff 更新的可服务对象很有用。
预期的版本
预期的版本代表了应加载并准备就绪的一组可服务版本。源一次为单个可服务流传递这组可服务版本。当源给出一组新的预期版本列表到管理器,它会代替可服务化流之前的列表。管理器卸载列表中不再显示的所有以前加载的版本。
更多细节可以参见高级手册以了解版本加载如何在实际中工作的。
管理器
管理器掌握着可服务化对象的全部生命周期,包括:
- 加载可服务化对象
- 服务可服务化对象
- 卸载可服务化对象
管理器监听所有的源和版本。管理器视图满足源的所有请求,但是在请求内容无法获得的情况下,也可能会拒绝载入一份预期版本。管理人员也可以推迟卸载。例如,基于确保始终加载至少一个版本的策略,一个管理器可能会等到新版本完成加载后再执行卸载。
TensorFlow 服务管理器提供了一个简单而狭窄的接口 GetServableHandle(),以便于加载可服务化对象实例。
核心
使用了标准的 TensorFlow 服务 API,TensorFlow 服务核心管理了可服务化对象的下面几个方面:
- 生命周期
- 度量标准 TensorFlow 服务核心把可服务化对象和加载器看成不透明的对象。
可服务化对象的生命周期
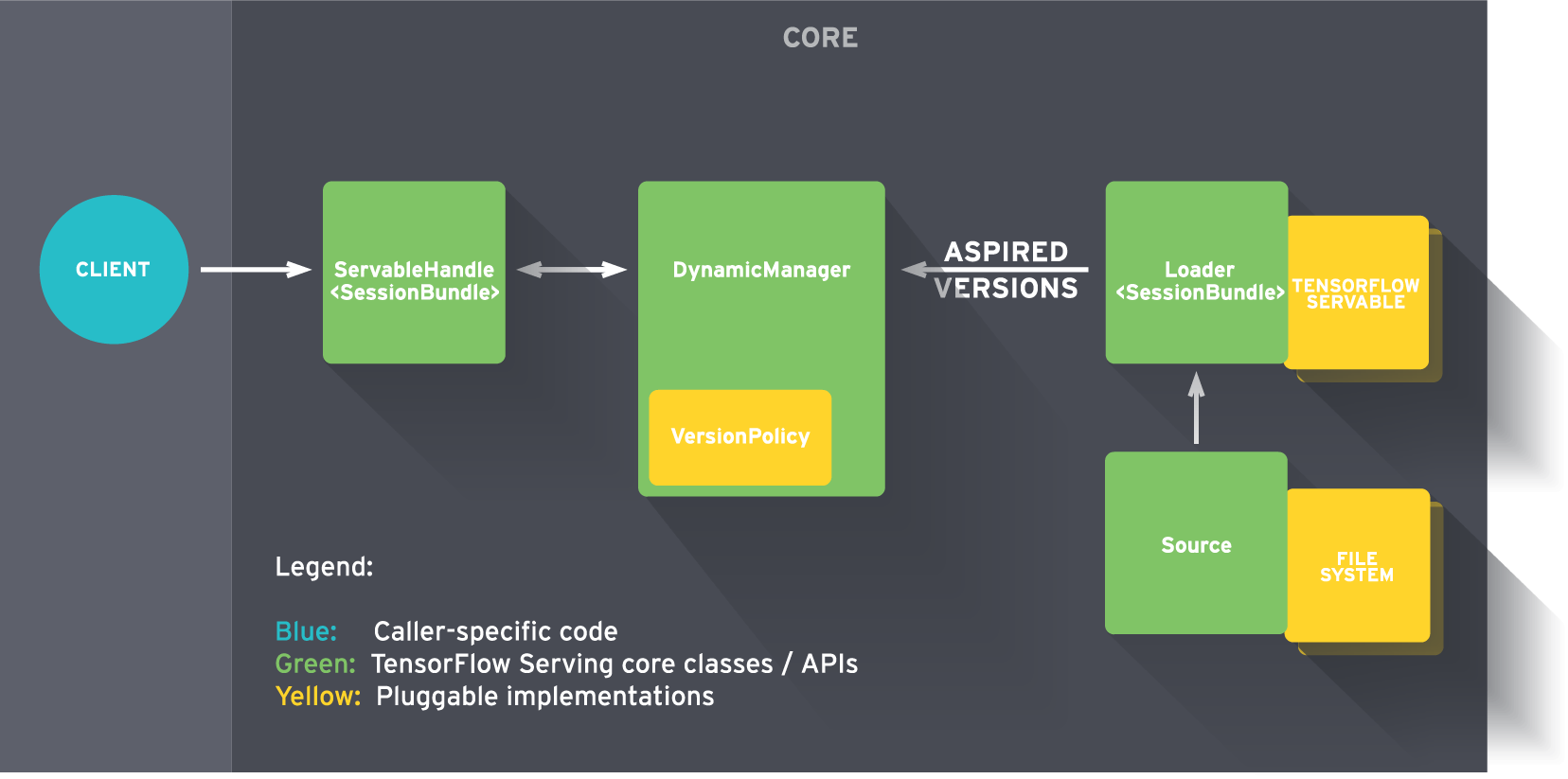
广义的来说:
- 源为可服务化版本创建了加载器
- 加载器发送预期版本给管理器,来加载和提供服务给客户端请求。
更详细的:
- 一个源组件为一个指定版本创建了加载器。这个加载器包含了它可能需要的提供给可服务化对象的所有的元素。
- 源通过使用一个回调去通知管理器预期版本
- 管理器应用配置版本策略去决定下一个执行的动作,这有可能是卸载一个之前加载的版本或者加载更新的版本
- 如果管理器确认以上是安全的,它将给加载器需要的资源,并通知加载器去加载新的版本
- 客户端询问可服务化对象管理器,指出了精确的版本或只是要求一个最新的版本。管理器返回一个可服务化对象的句柄。
例如,一个源展示了一个 TensorFlow 图频繁的更新模型的权重。这些权重的信息存储在磁盘的文件上。
- 源检测到一个新的模型权重版本。它创建了一个包含在磁盘上模型数据指针的加载器。
- 源会通知预期版本信息的动态管理器。
- 动态管理器应用了版本策略并决定了加载新的版本内容
- 动态管理器告诉加载器这里有足够的内存。加载器将 TensorFlow 图用新的权重实例化。
- 一个客户端请求一个最新模型的句柄,并且动态管理器返回一个最新可服务化对象的版本句柄给它。
可扩充性
TensorFlow 服务提供服务的扩展点,以供你可以增加新的功能。
版本策略
版本策略指定了加载版本的序列和用一个独立的服务流卸载。
TensorFlow 服务包括两个非常著名的用例策略。它们是可用性保留策略,避免加载零版本;通常在卸载就版本之前先加载新版本和资源保留策略,避免同时加载两个版本,因此需要双倍的资源;在加载一个新版本之前先卸载旧版本。为了简单地使用 TensorFlow 服务,当认为模型服务的可用性非常重要,而资源成本又很低的情况下,“可用性保留策略”将确保在卸载旧版本之前已加载并准备好新版本。TensorFlow 的复杂用法,例如,跨多个服务器实例管理版本,资源保留策略能做到使用最少的资源,而无需额外的缓冲区来加载新版本。
源
新资源可以支持新的文件系统,云产品和算法后端。TensorFlow 服务提供了一些常见的构建模块,可轻松快速地创建新资源。例如,TensorFlow 服务包括了一个实用工具实现将轮询行为包装在一个简单的源周围。源和特定的资源和数据托管服务器紧密相关。
有关如何创建自定义源的文档参见自定义源文档
批处理器
将多个请求批处理为单个请求可以显著的降低执行推理的成本,尤其是存在硬件加速器 GPU 的奇怪你看下。
TensorFlow 服务包含一个请求批处理的小部件,可以使客户端轻松地将跨请求地特定于类型地推理以批处理的方式变成批处理形式的请求,这样算法系统就可以更有效的进行处理。
更多信息见Batching Guide